Case studies
Depression Detection: Text Augmentation for Robustness to Label Noise in Self-reports
Enhancing Depression Detection: Text Augmentation Strategies for Resilience to Label Noise in Self-Reports - SEO: Depression Detection, Text Augmentation, Label Noise, Self-Reports
Get a quote
Summary
Depression, a widespread mental health issue affecting individuals in both affluent and developing regions, poses significant challenges at a societal level due to its profound impact on people's daily lives and overall well-being. It can lead to severe outcomes, including self-harm and suicide. Recent technological advancements, particularly in artificial intelligence (AI) and natural language processing (NLP), offer promising solutions for assessing depression. Utilizing the Bidirectional Encoder Representations from Transformers (BERT) model. We used Reddit Self-reported Depression Diagnosis dataset, for detecting depression without requiring expert intervention. We address the issue of label noise, which significantly affects the performance of transformer-based models, by introducing two innovative data augmentation techniques: Negative Embedding and Empathy. These methods enhance the model's ability to understand context and emotions through the strategic use of pronouns and depression-related vocabulary, making our approach highly relevant for AI-driven mental health applications. Our findings show a remarkable 31% improvement in detection accuracy with Negative Embedding over traditional BERT and DistilBERT models. By integrating advanced AI algorithms with natural language insights, we demonstrate that it is possible to achieve accurate depression detection in challenging data conditions, paving the way for more accessible and efficient mental health support systems.
Duration
3
Team Size
3
01
Challenges
Depression, a critical mental health challenge, impacts over 264 million individuals globally, manifesting through a spectrum of emotional and cognitive disturbances. Symptoms range from difficulties in concentration and decision-making to profound feelings of guilt and helplessness. In primary care settings, depression and anxiety disorders are common, yet detection rates are alarmingly low, with less than one-third of significant cases accurately identified. The COVID-19 pandemic has exacerbated this issue, leading to widespread psychological distress and sparking a public mental health crisis.
The scarcity of accessible mental healthcare services underscores the urgency of developing effective depression detection strategies to mitigate the risk of suicide and suicide attempts. Early identification of depression is crucial, enabling prompt intervention and potentially saving lives, especially during the pandemic and beyond.
In today's digital era, the internet has become a vital platform for individuals to discuss their experiences, obstacles, and mental health concerns. Platforms like Reddit and Twitter offer invaluable insights into mental health states through user-generated content. Leveraging natural language processing (NLP) and machine learning (ML) technologies, our approach involves analyzing this text data to pioneer a method for the early detection of depression. By automatically classifying online posts into depressed versus non-depressed categories, we aim to enhance our understanding of depression and improve early detection rates.
This innovative use of AI, NLP, and ML not only opens new pathways for understanding mental health but also offers a scalable, efficient solution for identifying depression early. By tapping into the wealth of data available on social media platforms, we can bridge the gap in mental healthcare access and provide timely support to those in need, demonstrating the transformative potential of AI in tackling global mental health challenges.
02
Innovation
In our AI-driven approach to mental health, we solve two tasks using advanced (a) Unsupervised learning to remove noise from the dataset and (b) Exploit contexts for robustness to label noise in detecting depression; we proposed two data augmentation methods, i.e., Negative Embedding and Empathy. The dataset consists of the Reddit Self-reported Depression Diagnosis (RSDD) dataset by web-scraping depressive and non-depressive statements from 2 subreddits, /depression and /AskReddits. A drawback of this method is label noise, a common challenge in AI models, particularly in mental health applications, resulting from mislabeling by non-experts or oversimplified labeling criteria. Oversimplified labeling criteria may lead to the mislabeling of a non-depressive statement in the /depression subreddit as depressed. Due to the pattern-memorization effects, label noise may significantly compromise the performance of deep learning models in classification tasks, particularly in detecting depression.
Based on the word cloud, words such as feel, depression, want, and friend are seen more frequently in the depressive samples. The word cloud of the lexicons generated by the Empath library demonstrates that the depressive samples include more affective words. Pronouns are also commonly observed in depressive samples.
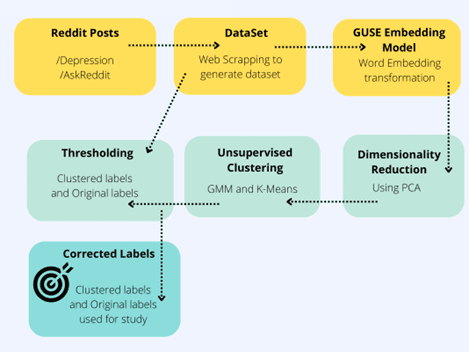
Pipeline for Label Correction. It starts with extracting the dataset, followed by the GUES embedding model, then applying dimensionality reduction, unsupervised clustering, and finally, label correction.
Word Embedding is a critical technique in text analysis, where words are transformed into real-valued vectors to capture their semantic meanings. This process allows for words with similar meanings to be positioned closely in vector space. In our study, we utilized the Google Universal Sentence Encoder (GUSE) for word embedding, transforming raw text data into numerical vectors. The GUSE model excels in encoding text into high-dimensional vectors, making it ideal for a variety of natural language processing (NLP) tasks, including text classification, semantic similarity, clustering, and more. Its design is particularly suited for processing longer text units, such as phrases, sentences, and short paragraphs.
To enhance the quality of our dataset by minimizing noise, we employed several unsupervised clustering algorithms. Given the high-dimensional nature of the data post-GUSE embedding, dimensionality reduction was a critical preliminary step. We utilized Principal Component Analysis (PCA) to combat the curse of dimensionality, ensuring that clustering algorithms perform effectively. Our approach incorporated both Gaussian Mixture Models (GMM) and K-means clustering to segment our dataset. GMM operates on the premise that all data points are derived from a finite mixture of Gaussian distributions with unknown parameters, making it a probabilistic model. Conversely, K-means is a centroid-based algorithm that assigns data points to clusters based on their distance to the nearest cluster centroid, thus simplifying the data structure into manageable clusters.
By applying these sophisticated clustering algorithms, we successfully categorized our data into two distinct clusters. These clusters were then used as labels for our model, facilitating a more structured and insightful analysis. This methodology underscores the potential of AI and machine learning in extracting meaningful patterns from complex datasets, showcasing the power of advanced NLP techniques in enhancing data analysis and model accuracy.
03
Impact
In refining the approach to understanding depression through language models, we innovated upon the conditional masked language model (MLM) framework utilized in BERT pre-training. This method traditionally incorporates segmentation embeddings, which we replaced with negative embeddings to better highlight depressive contexts. This adjustment is predicated on the presence of negative tokens, enhancing the model's ability to discern genuine instances of depression from noisy data. Negative embeddings assign a value of 1 for tokens indicative of negative sentiment and 0 for those that are not, refining the model's focus on depressive language cues within a given sequence.
Original Text | Lexicons | Post-processed Texts |
Wow. I understand that the rules are the rules, you just painted “everyone” who offers that as either a psycho or a predator. I must say I am feeling like one now because ... | hate, nervous, suffering, art, optimism, fear, zerst, speaking, sympathy, sadness, joy, lust, shame, pain,negative emotion, contentment, positive emotion, depression, pronoun, ... | Wow. I understand that the rules are the rules, you just pained ”everyone” who offers that as ... hate, nervous, suffering, art, optimism, fear, zest, speaking, sympathy, sadness, joy, lust, shame, pain, ... |
Our methodology calculates the likelihood of depressive sentiment, p(·|S\Σni), by considering the influence of a negative token ni, the overall sequence S, and the context of S/Σni. This approach leverages predefined negative tokens identified in prior sentiment analysis research, ensuring a targeted analysis of depressive contexts.
For the underlying architecture of our classification module, we chose BERT and DistilBERT as foundational elements. These architectures are characterized by their multi-layer, bidirectional transformer encoders and the implementation of multi-head attention mechanisms. Thanks to modern advancements in linear algebra frameworks, these Transformer architectures are highly optimized, particularly in terms of linear layers and layer normalization. It's noteworthy that variations in the tensor's last dimension, or the hidden size dimension, have minimal impact on computational efficiency within a fixed parameter budget, compared to other factors like the number of layers.
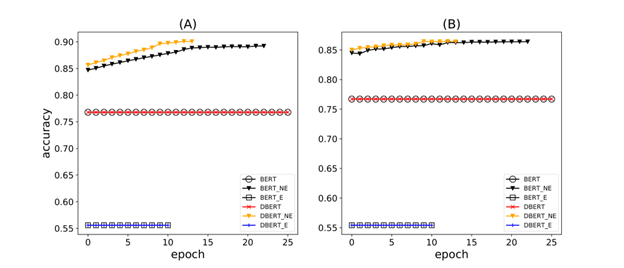 Accuracy during training when backbones are unfrozen. BERT with Negative Embedding and DistilBERT with Negative Embedding has the highest accuracy on (A) training and (B) validation sets. NE: Negative Embedding, E: Empathy, DBERT: DistilBERT
Accuracy during training when backbones are unfrozen. BERT with Negative Embedding and DistilBERT with Negative Embedding has the highest accuracy on (A) training and (B) validation sets. NE: Negative Embedding, E: Empathy, DBERT: DistilBERT
Our classification module integrates a global averaging layer, optimized with a pool size of 3 and a stride of 3, followed by two hidden fully connected layers containing 256 and 64 units, respectively. Each of these layers employs a rectified linear unit (ReLU) activation function, facilitating a nuanced and effective analysis of depression indicators within text data. This architecture, rooted in the pre-trained BERT-Base-Uncased and DistilBERT-Base-Uncased parameters, underscores our commitment to leveraging AI and machine learning innovations for the nuanced detection of mental health conditions.
Using Negative Embedding and Empathy in BERT-based architectures on label noise is a novel approach. Models on Negative Embeddings achieved a higher F1 score (approximately 87%) compared to earlier studies, where Word2Vec and fastText embeddings were used on a sparse dataset, and an F1 score of 35% on average was observed. Future studies will investigate multimodal datasets that include speech and text data essential in emotion recognition to detect depression. For more information or to share your perspectives on advancing the capabilities of our AI solution, feel free to contact us.
Impact metrics
Our impact in the vertical
Quantifying our success to showcase how we bring transformative AI solutions to healthcare
3X
Patient wait time decrease
40%
Average treatment cost reduction
30%
Increased patient satisfaction score
case studies
Data Assessment Success Stories
How Our Swift Path Methodology Drives Real-World Impact
Convinced? Get in touch
Get a quote